It's pretty straight forward. Following is the code...
In this tutorial will try to parse out infobox for Tom Cruise:
Response res = Jsoup.connect("http://en.wikipedia.org/wiki/Tom_Cruise").execute();
String html = res.body();
Document doc2 = Jsoup.parseBodyFragment(html);
Element body = doc2.body();
Elements tables = body.getElementsByTag("table");
for (Element table : tables) {
if (table.className().contains("infobox")==true) {
System.out.println(table.outerHtml());
break;
}
}
table.outerHtml() will output HTML, which displays following:

If you need to parse out a specific element only, you can again use JSOUP to do so.
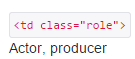
Let's say you need to get content of Occupation, this is how you can extract the text:
String Occupation = doc.select("td[class=role]").first().text();
String Occupation will contain the text: Actor, producer