This short post talks about the PID services and how they are used in all components of Big Data Architecture Framework.
**Persistent Identifier (PID) services **
A critical function that spreads across all parts of BDAF (infrastructure, analytics, models, lifecycle management as well as in the big data security) is a need for a quality data indexing and search abilities. These are crucial because we need to be able to efficiently index and search through data sets.
The service that is commonly used to provide assistance with the issue of indexing and searching is called the Persistent Identifier (PID) services. Persistent identifiers are increasingly often seen as the core component for all the many references we are creating at various levels - this can range from references between metadata descriptions and their resources up to references between semantic assertions. PID offers a robust data identification for items within the massive data collection catalogs as well as for data service endpoint URLs.
In general, a persistent identifier (PID) is a long-lasting reference to a document, file, webpage, or another object. It’s very often used in the environment of Internet digital objects, such as web pages. Typically, PID’s are not just the references, but also actionable items, that can be plugged into a web browser, allowing a user be taken to the recognized source.
A very significant characteristic of persistent identifiers is that "persistence is purely a matter of service." (Kunze, J., Rodgers, R. and 1, rfcmarkup version, 2013), which means that persistent identifiers are only persistent to the degree that someone commits to resolving them for users. “No identifier can be inherently persistent.” (Persistent identifier, 2016).
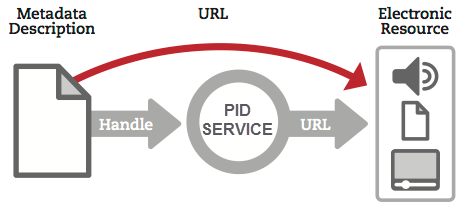
Image from Clarin Project - GRNET persistent iDentifier service (2017)
The PIDs typically consist of two parts, separated by a forward slash “/”. “The first part or prefix indicates where the data set is stored (that is, which data center it is stored at) and the suffix is a string of characters (mostly letters and digits) that is unique to that particular data set.” (Demystifying PIDs, 2017).
Examples of PID Usage
One of the most notable users of PID services is The National Computing Infrastructure (NCI) in Australia. NCI Australia is the nation’s most highly integrated, high-performance research computing environment. As Australia’s national research computing facility, NCI provides world-class services to Australian researchers, industry, and government. The most important in this context is their relation to Big Data, as they manage over 10PB of research data, which is co-located with Top 100 high performance computer for fast processing (Raijin – comprised of 57,864 cores at 2.6 GHz, 3602 compute nodes, 56 NVIDIA Tesla K80 GPUs, 162 TBytes of main memory, Mellanox FDR 56 Gb/sec Infiniband and 12.5 PBytes of high-performance operational storage capacity). “The NCI's data platform services include building catalogs, DOI mining, data curation, data publishing, and data delivery services.” (Wang, J., Si, W., Car, N. and Evans, B., 2016). NCI claims that their approach to utilizing a PID management tool, known as the PID Service, helped them tremendously to manage its persistent identifiers.
Another example of using PID’s comes from EUDAT. EUDAT provides services for managing European research data files. They work with lots of different research communities and institutions across Europe, and hence the data files managed by their services could potentially be stored in a data center anywhere in Europe. To keep track of where the data files are stored physically, they assign a persistent identifier (PID) to each set of data that is stored. In the case of NCI, also EUDAT is using PID to make sure that each data set has its own unique identifier.
References
Infrastructure, N.C. (2017) Welcome to NCI - national computational infrastructure. Available at: https://nci.org.au/ (Accessed: 17 January 2017).
Wang, J., Si, W., Car, N. and Evans, B. (2016) Persistent identifier practice for big data management at NCI. Available at: https://cms.nci.org.au/?q=publication/4750 (Accessed: 17 January 2017).
Infrastructure, N.C. (2015) Raijin - national computational infrastructure. Available at: http://nci.org.au/systems-services/national-facility/peak-system/raijin/ (Accessed: 17 January 2017).
Persistent identifier (2016) in Wikipedia. Available at: https://en.wikipedia.org/wiki/Persistent_identifier (Accessed: 17 January 2017).
Kunze, J., Rodgers, R. and 1, RFC markup version (2013) The ARK identifier scheme. Available at: https://tools.ietf.org/html/draft-kunze-ark-18 (Accessed: 17 January 2017).
Demystifying PIDs (2017) Available at: https://www.eudat.eu/news/demystifying-pids-and-getting-handle-handles (Accessed: 17 January 2017).
GRNET persistent iDentifier service (2017) Available at: http://epic.grnet.gr/ (Accessed: 17 January 2017).