Splunk Enterprise is presumably one of the best platforms for gaining real-time intelligence from data. The following short tutorial explains how to install Splunk server (on Windows or Linux server) and how to use Python to programmatically query Splunk and visualize Apache data by plotting them on a graph by using the Matplotlib library. In this post, show step by step, how to add Apache logs to Splunk, and illustrate how relatively easy is to use Python to query how much bandwidth was consumed by one of my websites (in the past week, in megabytes).
Splunk Server Installation (Windows/Linux)
Windows Installation
If you're using XAMPP and want to monitor Apache logs with Windows, we'll need to install Splunk Enterprise on Windows box. You can do this for free, as we get a Splunk Enterprise license for 60 days that lets you index up to 500 megabytes of data per day. After 60 days you can convert to a perpetual free license or purchase a Splunk Enterprise license. To download Splunk, go to https://www.splunk.com/en_us/download/splunk-enterprise.html and simply select the Windows, Linux or Mac OS installation:
Windows installation file is approx. 200 MB and by default Splunk is installed into C:\Program Files\Splunk\ directory.
Once installed, Splunk will be available at the following internal address: http://localhost:8000 and look like this:
Centos 7 or Amazon Linux Installation
The following instructions are for those running Apache on Linux and want to monitor their Apache logs locally - directly from the Linux box. To do so, simply download Splunk Enterprise for free, you get a Splunk Enterprise license for 60 days that lets you index up to 500 megabytes of data per day. After 60 days you can convert to a perpetual free license or purchase a Splunk Enterprise license. To download Splunk, go to https://www.splunk.com/en_us/download/splunk-enterprise.html
The file to download has the TGZ extension and will be named something like this: splunk-7.2.6-c0bf0f679ce9-Linux-x86_64.tgz, depending on the current stable version of Splunk.
Copy splunk-7.2.6-c0bf0f679ce9-Linux-x86_64.tgz file over to your /tmp directory, then run the following commands to run the installation
TO CREATE SPLUNK GROUP AND USER AND LOGIN AS SPLUNK USER
$ groupadd splunk $ useradd -d /opt/splunk -m -g splunk splunk $ su - splunk
NAVIGATE TO TMP DIRECTORY, UNTAR THE INSTALLATION FILE AND COPY SPLUNK TO /opt/splunk DIRECTORY
$ cd /tmp $ tar -xvf splunk-7.2.6-c0bf0f679ce9-Linux-x86_64.tgz $ cp -rp splunk/* /opt/splunk/
SET THE PERMISSIONS, THEN START THE SPLUNK SERVER
$ chown -R splunk: /opt/splunk/ $ cd /opt/splunk/ $ cd bin $ ./splunk start --accept-license
Once above is done, you'll have the Splunk running on the local system of whatever is your IP address, likely at http://localhost:8000 or your server's http://your-server-ext-ip:8000:
The last step usually is to enable the port 8000 and also 8089 (API for programmatic access) in your firewall. On your Centos install you can add a permanent rule to firewall like this: firewall-cmd --add-port=8000/tcp --permanent firewall-cmd --add-port=8089/tcp --permanent
On Amazon Linux, you can do the exception for port 8000 and 8089 through AWS interface.
Once done, you should be able to access Splunk interface through the browser:
And port 8000 and 8089 are configured in Server settings » General settings:
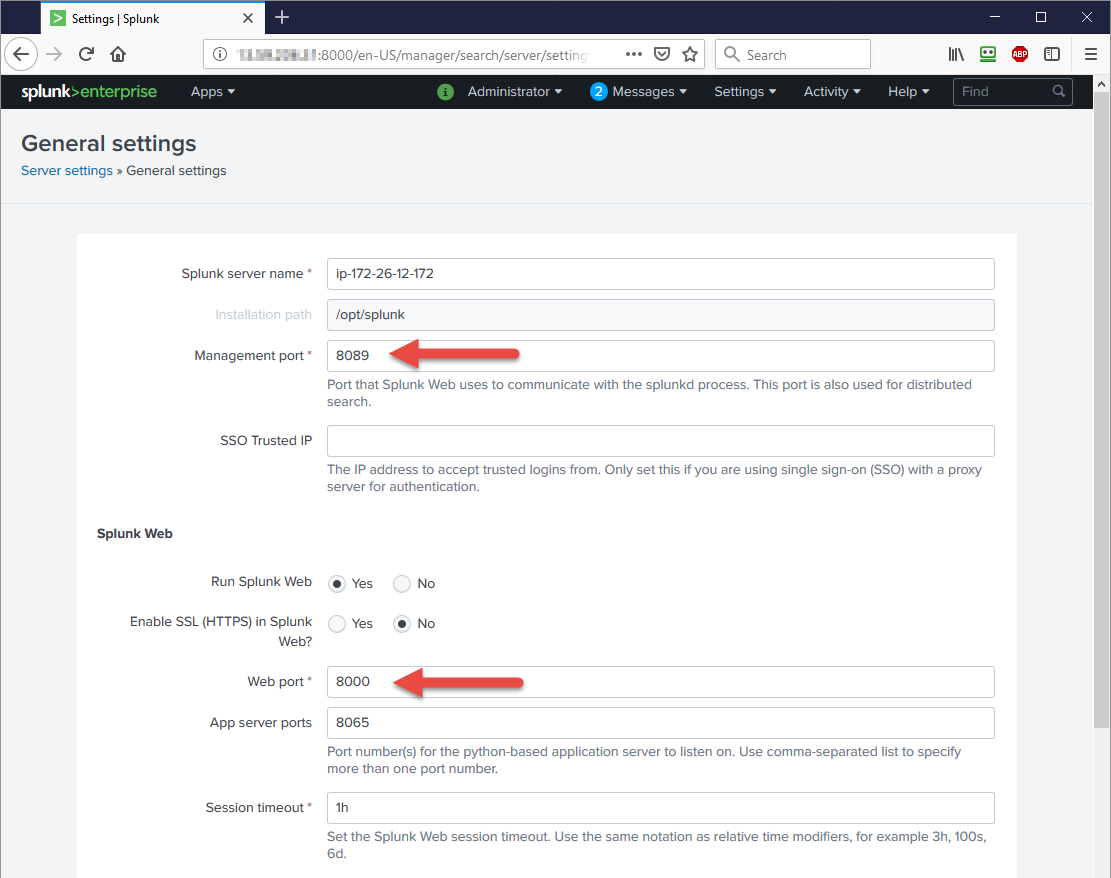
ADDING APACHE LOGS TO SPLUNK
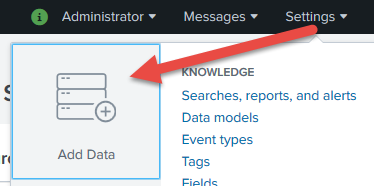
Now, let's add our Apache logs to Splunk. To do so, login to Splunk server interface and select: Settings, then choose an option to 'Add Data':
Scroll towards the bottom and select the option to monitor files:
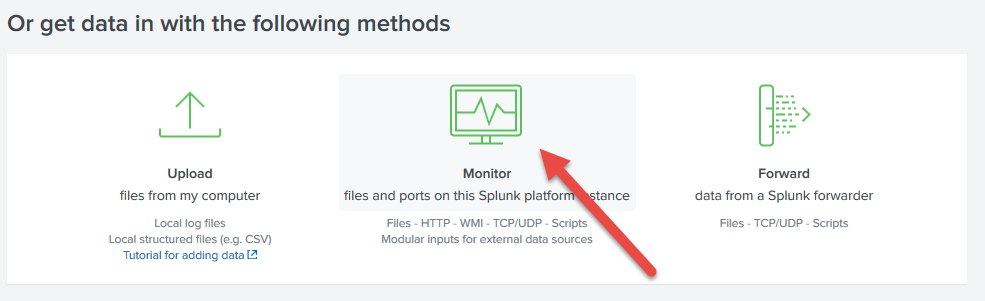
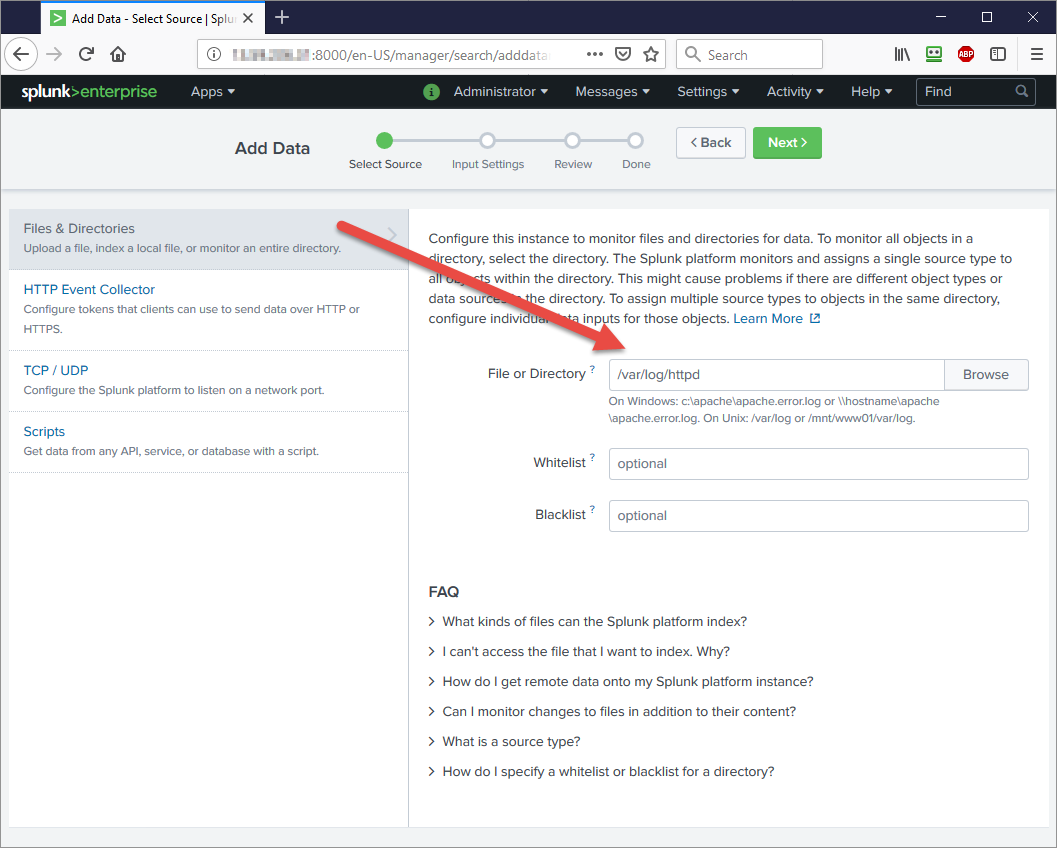
Then, under Files & Directories, you can enable monitoring of an entire directory.
Add in your /var/log/httpd or wherever your Apache logs are:
Once successfully added, you'll get a message that the 'File input has been created successfully':
QUERING SPLUNK FROM THE SPLUNK INTERFACE
Now that we have Apache logs inside Splunk, let's do some simple query.
Let's say I want to know how much bandwidth was consumed by one of my websites (joe0.com) in the past 7 days, including today, in megabytes.
To do so, I can run a Splunk query like this:
source::/var/log/httpd/* joe0.com earliest=-7d@d | eval megabytes = bytes/1024/1024 | timechart sum(megabytes)
Which produces expected results that outline the daily bandwidth usage of joe0.com website:
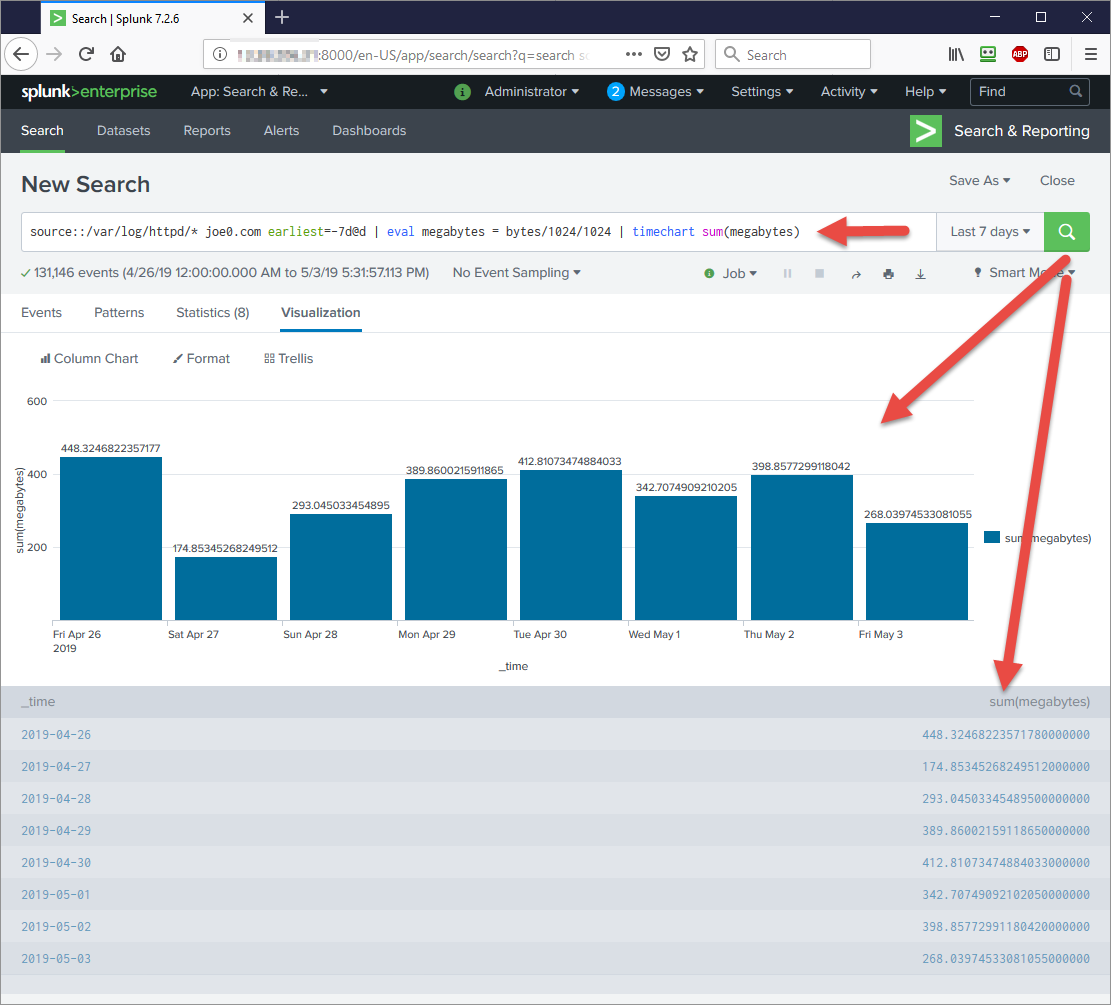
That's cool, I just learned that I on a regular business day, my site joe0.com requires on average less than half a GB of bandwidth. That's useful.
But how about if we want to run the same query, not from the Splunk interface, but instead by using Python?
Programmatic access to Splunk can surely be useful at times when running queries through Splunk interface are not sufficient for our purposes.
HOW TO QUERY SPLUNK BY USING PYTHON PROGRAMMING LANGUAGE
Ok, so now we're finally getting to the meat of the article. Let's replicate the same 'total bandwidth per day' report, but use Python to query the Splunk database.
Let's start by creating a new project in our IDE and creating a new python file called: pythonsplunk.py:
Install the package: 'splunk-sdk' and 'matplotlib' by running the following command first: pip3 install splunk-sdk pip3 install matplotlib pip3 install numpy
- **Splunk-SDK: **With the Splunk SDK for Python, you can write Python applications to programmatically interact with the Splunk engine. The SDK is built on top of the REST API, providing a wrapper over the REST API endpoints. So that means with fewer lines of code, you can write applications that:
Search your data, run saved searches, and work with search jobs.
- Manage Splunk configurations and objects.
- Integrate search results into your applications.
- Log directly to Splunk.
- Present a custom UI.
- **Matplotlib:** Matplotlib is a Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms. Matplotlib can be used in Python scripts, the Python and IPython shells, the Jupyter notebook, web application servers, and four graphical user interface toolkits.
- **NumPy:** is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays.
Once both libraries are installed, let's start our code by importing the above-mentioned libraries. Also, note, we'll be using DateTime library, which is required for date time parsing.
import matplotlib.pyplot as plt
import numpy as np
import splunklib
import splunklib.client as client
import splunklib.results as results
from datetime import datetime
On the next lines, we define the connection details and credentials to our Splunk Server:
HOST = "Splunk Server IP Address"
PORT = 8089
USERNAME = "admin"
PASSWORD = "your password"
Next, we establish a service connection to the Splunk server, with above details:
service = client.connect(host=HOST, port=PORT, username=USERNAME, password=PASSWORD)
Now, we're ready to create a result reader and query Splunk for the daily bandwidth usage of joe0.com website
rr = splunklib.results.ResultsReader(
service.jobs.export("search joe0.com earliest=-6d@d | eval megabytes = bytes/1024/1024 | timechart sum(megabytes)"))
Let's create two arrays, one which will hold the dates and one for values (megabytes) we get from Splunk:
dates = []
values = []
Now, let's connect to Splunk and then read the results of our Splunk query:
for result in rr:
if isinstance(result, results.Message):
# Diagnostic messages may be returned in the results
print('%s: %s' % (result.type, result.message))
elif isinstance(result, dict):
# Normal events are returned as dicts
print(result)
else:
print("Job is finished. Results are final.")
The result will look like this:
python.exe C:/0.code/PythonSplunk/pythonsplunk.py
OrderedDict([('_time', '2019-04-27 00:00:00.000 EDT'), ('sum(megabytes)', '174.85345268249512000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-04-28 00:00:00.000 EDT'), ('sum(megabytes)', '293.04503345489500000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-04-29 00:00:00.000 EDT'), ('sum(megabytes)', '389.86002159118650000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-04-30 00:00:00.000 EDT'), ('sum(megabytes)', '412.81073474884033000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-05-01 00:00:00.000 EDT'), ('sum(megabytes)', '342.70749092102050000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-05-02 00:00:00.000 EDT'), ('sum(megabytes)', '262.95024108886720000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-05-03 00:00:00.000 EDT'), ('sum(megabytes)', '89.37751579284668000000'), ('_span', '86400'), ('_spandays', '1')])
DEBUG: Configuration initialization for /opt/splunk/etc took 8ms when dispatching a search (search ID: 1556935409.633)
DEBUG: base lispy: [ AND com joe0 ]
DEBUG: search context: user="admin", app="search", bs-pathname="/opt/splunk/etc"
INFO: Your timerange was substituted based on your search string
OrderedDict([('_time', '2019-04-27 00:00:00.000 EDT'), ('sum(megabytes)', '174.85345268249512000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-04-28 00:00:00.000 EDT'), ('sum(megabytes)', '293.04503345489500000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-04-29 00:00:00.000 EDT'), ('sum(megabytes)', '389.86002159118650000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-04-30 00:00:00.000 EDT'), ('sum(megabytes)', '412.81073474884033000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-05-01 00:00:00.000 EDT'), ('sum(megabytes)', '342.70749092102050000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-05-02 00:00:00.000 EDT'), ('sum(megabytes)', '398.85772991180420000000'), ('_span', '86400'), ('_spandays', '1')])
OrderedDict([('_time', '2019-05-03 00:00:00.000 EDT'), ('sum(megabytes)', '309.33188915252686000000'), ('_span', '86400'), ('_spandays', '1')])
Job is finished. Results are final.
As we can see, there is some weird thing happening that Splunk produces the results twice in the row.
In order to get around it, I've implemented a different way to list the results, that implements parsing the values that occur after the information message "INFO: Your time range was substituted based on your search string" and one that also formats the dates and results and adds them into arrays:
for result in rr:
if isinstance(result, results.Message):
if result.message == "Your timerange was substituted based on your search string":
startPrint = True
elif isinstance(result, dict):
parsedDate = str(list(result.values())[0]).replace(' 00:00:00.000 EDT', '')
dt: datetime = datetime.strptime(parsedDate, '%Y-%m-%d')
splunk_date = dt.strftime("%a, %b %d %Y")
splunk_value = list(result.values())[1]
if startPrint:
dates.append(splunk_date)
values.append(round(float(splunk_value), 2))
print(splunk_date + " - " + splunk_value)
Which results in a greatly improved format of the output:
python.exe C:/0.code/PythonSplunk/pythonsplunk.py
Sat, Apr 27 2019 - 174.85345268249512000000
Sun, Apr 28 2019 - 293.04503345489500000000
Mon, Apr 29 2019 - 389.86002159118650000000
Tue, Apr 30 2019 - 412.81073474884033000000
Wed, May 01 2019 - 342.70749092102050000000
Thu, May 02 2019 - 398.85772991180420000000
Fri, May 03 2019 - 311.12334632873535000000
Process finished with exit code 0
VISUALISING SPLUNK DATA USING MATPLOTLIB
Now, we can work with that and use the Matplotlib library to plot the dates and values on the bar graph.
This can be done, but adding the following code to our program:
# set the width of the bar relative to space in each of the column - 0.5 is half of the available space
bar_width = 0.5
# make a grey grid and dim the opacity to 20 percent
plt.grid(color='grey',alpha=0.2)
# add a title to our plot
plt.title('Joe0.com - Bandwidth Usage by Date (past week)', color='red')
# set the y label to 'Megabytes'
plt.ylabel('MegaBytes', color='green')
# create bars, center each bar, color it green and set the opacity to about half of the maximum
bar = plt.bar(np.arange(len(values)) + bar_width, values, bar_width, align='center', alpha=0.5, color='green')
# plot name of the dates and rotate them by 45 degrees
plt.xticks(range(len(values)), dates, rotation=45)
# add the bandwidth value (in MB) headings, place them above each of the bars
i = 0
for rect in bar:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2.0, height, values[i], ha='center', va='bottom')
i = i + 1
# show the graph
plt.show()
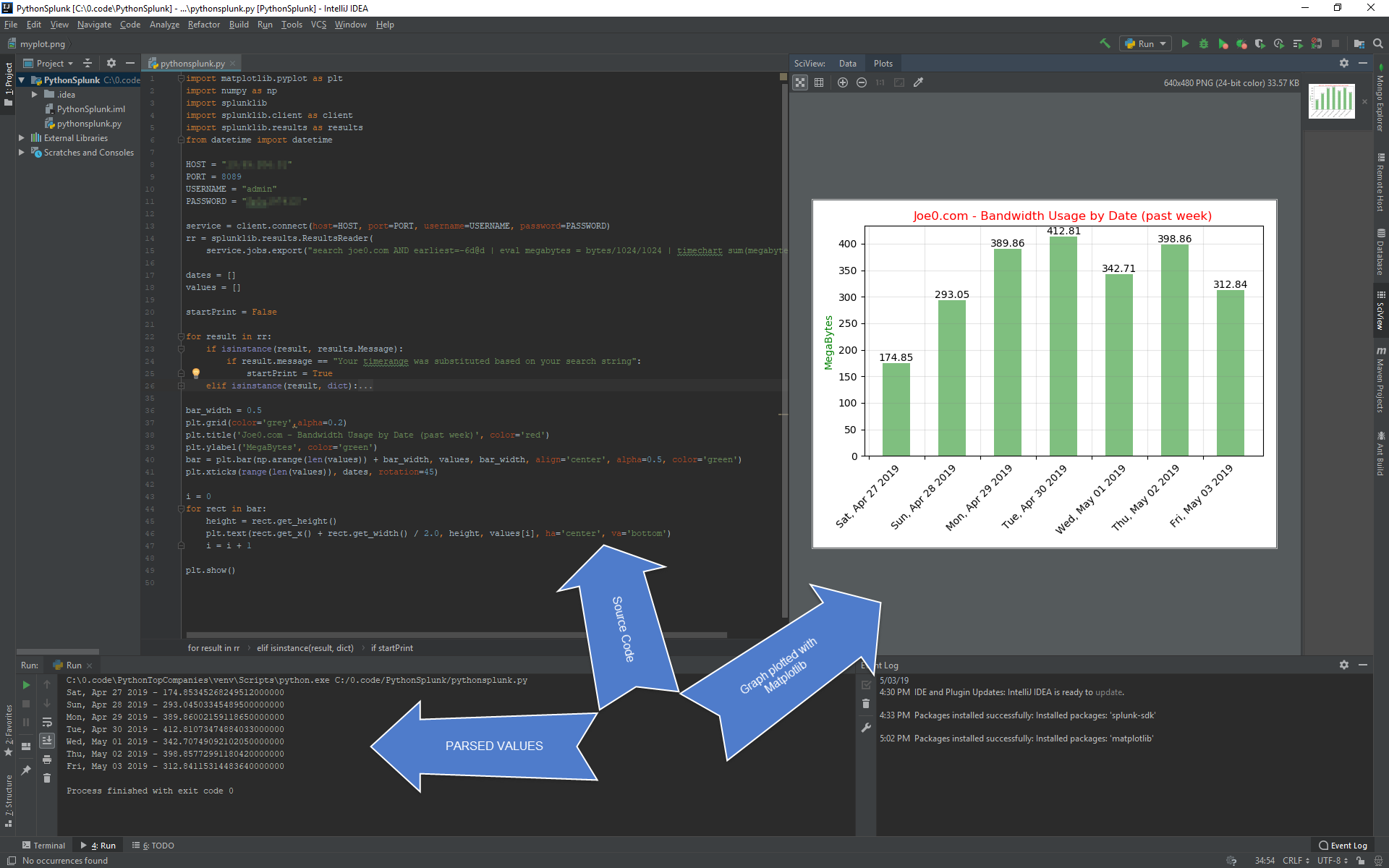
If we run the program now, voila, we've programmatically plotted the bandwidth values extracted from Splunk onto a graph by using Matplotlib library, here is what the result looks like:
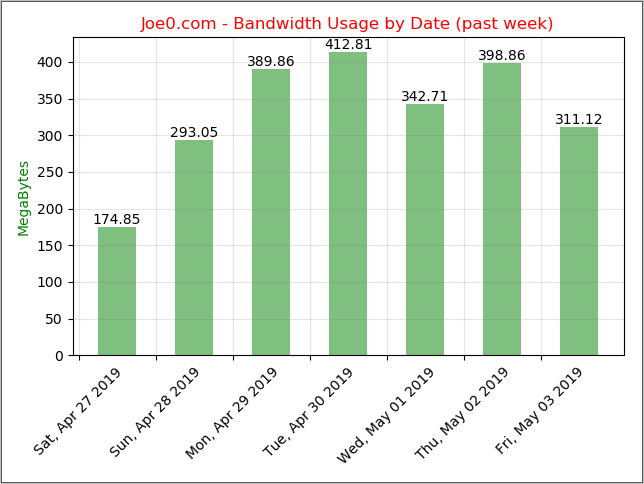
Screenshot from the IDE:
SOURCE CODE
Source code is posted to Github https://github.com/JozefJarosciak/PythonSplunk and also here: import matplotlib.pyplot as plt import numpy as np import splunklib import splunklib.client as client import splunklib.results as results from datetime import datetime
HOST = "IP ADDRESS OF SPLUNK SERVER" PORT = 8089 USERNAME = "admin" PASSWORD = "PASSWORD"
service = client.connect(host=HOST, port=PORT, username=USERNAME, password=PASSWORD) rr = splunklib.results.ResultsReader( service.jobs.export("search joe0.com AND earliest=-6d@d | eval megabytes = bytes/1024/1024 | timechart sum(megabytes)"))
dates = [] values = []
startPrint = False
for result in rr: if isinstance(result, results.Message): if result.message == "Your timerange was substituted based on your search string": startPrint = True elif isinstance(result, dict): parsedDate = str(list(result.values())[0]).replace(' 00:00:00.000 EDT', '') dt: datetime = datetime.strptime(parsedDate, '%Y-%m-%d') splunk_date = dt.strftime("%a, %b %d %Y") splunk_value = list(result.values())[1] if startPrint: dates.append(splunk_date) values.append(round(float(splunk_value), 2)) print(splunk_date + " - " + splunk_value)
bar_width = 0.5 plt.grid(color='grey',alpha=0.2) plt.title('Joe0.com - Bandwidth Usage by Date (past week)', color='red') plt.ylabel('MegaBytes', color='green') bar = plt.bar(np.arange(len(values)) + bar_width, values, bar_width, align='center', alpha=0.5, color='green') plt.xticks(range(len(values)), dates, rotation=45)
i = 0 for rect in bar: height = rect.get_height() plt.text(rect.get_x() + rect.get_width() / 2.0, height, values[i], ha='center', va='bottom') i = i + 1
plt.show()